Unified communications infrastructures have always been complicated, but in today's working world, that complexity has increased in leaps and bounds for numerous reasons.
The global adoption of hybrid working models has added new meaning to the word troubleshooting, and even troubleshooting techniques have been forced to transform from reactive, after-the-fact measures, to preventive maintenance procedures.
Every business needs their UC systems running properly, and adequate measures in place to fix them when they don't. Downtime, outages, equipment failures and sub-par voice and video quality costs valuable time and money. But while there are many common problems with any number of possible causes, not all issues, or the means to fix them are immediately obvious to maintenance personnel.
In this guide, we'll cover many of the computer problems that maintenance technicians will likely face, including unexpected equipment breakdown, device and asset performance, and the basic steps to identify and fix issues.
Experiencing webcam problems? Read our guide: Camera Troubleshooting: Common Webcam Problems & How To Fix Them
What is maintenance troubleshooting?
The maintenance troubleshooting process exists solely because of unexpected equipment failure. This can include anything from a mobile device malfunction, to Network Jitter, or a computer issue, to the breakdown of entire operating systems.
Find out more about Network Latency, Jitter and Packet Loss
Maintenance troubleshooting itself is a systematic approach to problem-solving, in an attempt to determine the root cause of issues with an operating system, a particular asset within the system, or the devices, applications and software stacks associated with those systems.
The job of a maintenance team is obviously to track down where the problem occurred, fix it, and implement corrective actions to prevent it from happening again, and then test, test, test.
Effective troubleshooting methodologies involve gathering information, or data that can help with isolating the problem, diagnosing potential causes as to why the failure occurred, and implementing the right solutions to fix it.
Maintenance troubleshooting techniques
From a service provider or maintenance teams point of view, basic maintenance troubleshooting techniques consist of a multi-faceted process, involving both a human element, and the deployment of performance management technology.
There are many components to the troubleshooting process, and multiple reasons why an asset breaks down, so for the purposes of this guide, we'll reduce the process to some basic, systematic steps:
Gathering information to identify the problem and start the troubleshooting process
While this may seem glaringly obvious, gathering information on where and when a problem occurs and how to fix it, is often challenging for maintenance teams. They'll first need to determine what went wrong; for example, a repeatedly dropped connection, poor quality audio or video, or an inability to connect at all. Identifying the underlying problem, or what's actually causing the symptoms to manifest themselves could involve:
- Inspecting log files. Log files contain data about the system, including applications and services, and this information helps troubleshoot issues or monitor system functions.
- Asking detailed questions about when symptoms were first noticed. For example, 'Did the problem occur when you performed a specific action?' This can help reveal if there are any patterns related to the problem.
- Possibly asking users to re-create the issue to see if something within the system has changed, which could have caused the problem, or if it's the same error that occurs repeatedly.
Read our UC Troubleshooting Guide for Pros
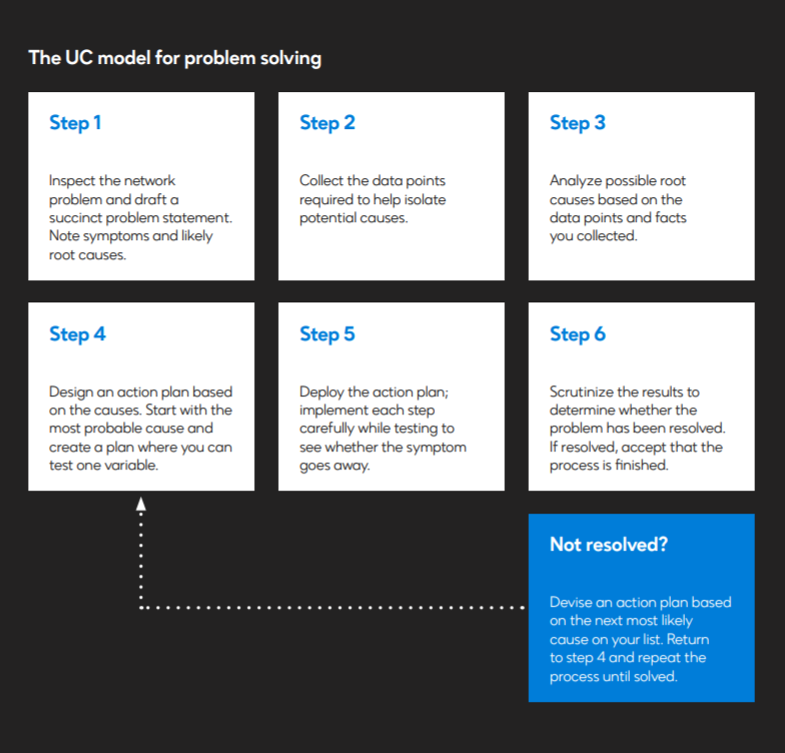
Establishing what causes computer problems in the first place
Once you determine what the problem is, it's time to create a list of probable causes, from most likely to least likely. For example, question the obvious in the case of a power issue at a workstation. Is the power cord plugged into the electrical outlet, and if so, is there actually power going to the workstation? Or, if it is a power issue, could it be that your surge protector isn't turned on?
Image source: CPacket
The above example is of course over-simplified, and to determine the probable cause of technical issues in a complex unified communication infrastructure involves much more in-depth analysis, some state-of-the-art performance management and monitoring solutions, as well as a great deal of trial and error.
A maintenance technicians checklist for tracking down problems and possible causes
Image source: Microsoft
While finding the cause of a problem can be difficult and time-consuming, a logical and methodical checklist can be extremely effective:
1. User error: Incorrect assumptions on a user's part as to how systems, equipment or applications work, can be part of the problem. It's essential to gather information, including detailed notes and user observations to see if operator error is the problem.
2. Software-related problems: Incompatible, or outdated software, duplicate system files, extension conflicts and other software issues can cause error messages, failure codes and system malfunction. It's always advisable to check for software issues before looking at the hardware aspect. Software testing can provide insight as well as detect and repair many software related issues.
3. Viruses and malware: Even with the most high-tech anti-virus software, operating systems can fall victim to infection, possibly through email attachments and other downloaded files. Maintenance troubleshooting teams should ask users if they've:
a) Recently received software from a common source or another user
b) Experienced any issues before receiving this software
c) Shared the file with others, and if so, are they experiencing the same problems
It's essential to determine whether all virus protection software is current, find the original source file and delete it, then reinstall all affected system and application software.
4. Hardware issues: If software, viruses and user error have been ruled out, hardware equipment breakdowns could be the remaining problem. This could be related to CMOS, RAM, hard drive, frozen screens, or even a computer failing to turn on at all. One of the obvious solutions to avoid common PC hardware problems is to prioritize preventive maintenance and deploy regular performance testing solutions.
Image source: TechTarget
Find out more about preventative maintenance and how to test your systems with our Definitive Guide To Performance Testing
The importance of root cause analysis in maintenance troubleshooting
At the core of basic maintenance troubleshooting techniques, is Root Cause Analysis (RCA). When something goes wrong in a major network or infrastructure, a systematic approach helps engineers, senior technicians and developers find the root of the failure and ultimately, determine the solution.
Troubleshooting using RCA is based on the premise that being reactive (or putting out fires in response to problems) is not the most effective maintenance troubleshooting technique or solution.
While an online search, or a process of elimination can often identify the solution to most common individual problems, it's just a fact that many malfunctions are more complicated and can affect multiple components. In this case, it might be necessary to identify the root cause of the problem before fixing individual issues.
RCA is about working to determine how, where, and why the issue appeared, responding to that answer, and creating a solution or series of solutions to prevent it from happening again.
Image source: Researchgate
How to perform RCA
An RCA roadmap may look slightly different across organizations and industries. But there are a few key steps that are needed to perform effective RCA:
1. Define the issue. Containing and/or isolating all parts of the problem is the first step.
2. Gather data. Once you've identified the problem, compile data and evidence to determine and properly understand what could possibly be the cause, including contributing issues.
3. Determine root problem. RCA techniques help find small clues that may reveal what went wrong.
4. Implement the solution. Using RCA techniques, you may find that there are one or several solutions which can be implemented immediately, or may require some additional work. Either way, RCA isn’t done until you’ve implemented a solution.
5. Document actions taken. After you’ve identified and solved the root problem, document the overall resolution. This documentation allows future maintenance technicians to use it as a resource.
6 Steps to performing RCA
What are failure codes?
Failure codes are simply alphanumeric codes which specifically address the reason an asset breaks down.
Failure codes enable technicians to quickly access a pre-set code to explain what went wrong and fix it. Failure codes also standardize data on unexpected equipment breakdowns and help to determine what the most common causes of the failure are.
By cataloguing repairs this way, maintenance troubleshooting teams can spot the trends that will help prevent the same thing from happening again in the future.
The importance of a real time monitoring and performance management solution
Finding a computer or network problem within your UC environment, and resolving it is all part of the maintenance troubleshooting process. But the key to quickly and efficiently finding computer, network, application or equipment issues is having the right tools on hand to identify problems in real time.
As we've already mentioned, RCA techniques determine how, where, and why issues appear, and allow you to create a solution to prevent those issues from happening again. Knowledge gives you control, so the more data you collect and analyze, the greater the likelihood of developing a correct and proactive diagnosis and solution.
Troubleshooting is an ongoing process, so the need for performance testing tools and real time performance monitoring to pick up and report on changes within your UC network is crucial.
Performance monitoring can not only keep track of asset performance, but help you create an asset history, which can give you an edge on maintenance troubleshooting in many ways. For example network issues can often occur within your network equipment or devices such as Firewalls, Routers, Switches, Wifi APs. Problems can be due to bad configurations, faulty connections, and even packet loss. Monitoring any SNMP-enabled network devices with a third-party real time monitoring solution will diagnose network problems affecting those devices.
How IR can help
Whether it's a faulty power cable, an incompatible device, network bottleneck or an IP address conflict, IR Collaborate delivers real-time proactive monitoring, troubleshooting, and analytics for on-prem and cloud-based collaboration systems.
Our state-of-the-art interactive dashboards provide real time visibility throughout your entire network from a single pane of glass, giving you the ability to solve issues, and repair breakdowns fast.
Why choose Collaborate for maintenance troubleshooting?
More than 600 organizations in over 60+ countries, including some of the world’s largest banks, airlines and telecommunications companies, rely on IR Collaborate to provide business critical monitoring and insights and ensure optimal performance and user experience for their customers across the globe 24x7.